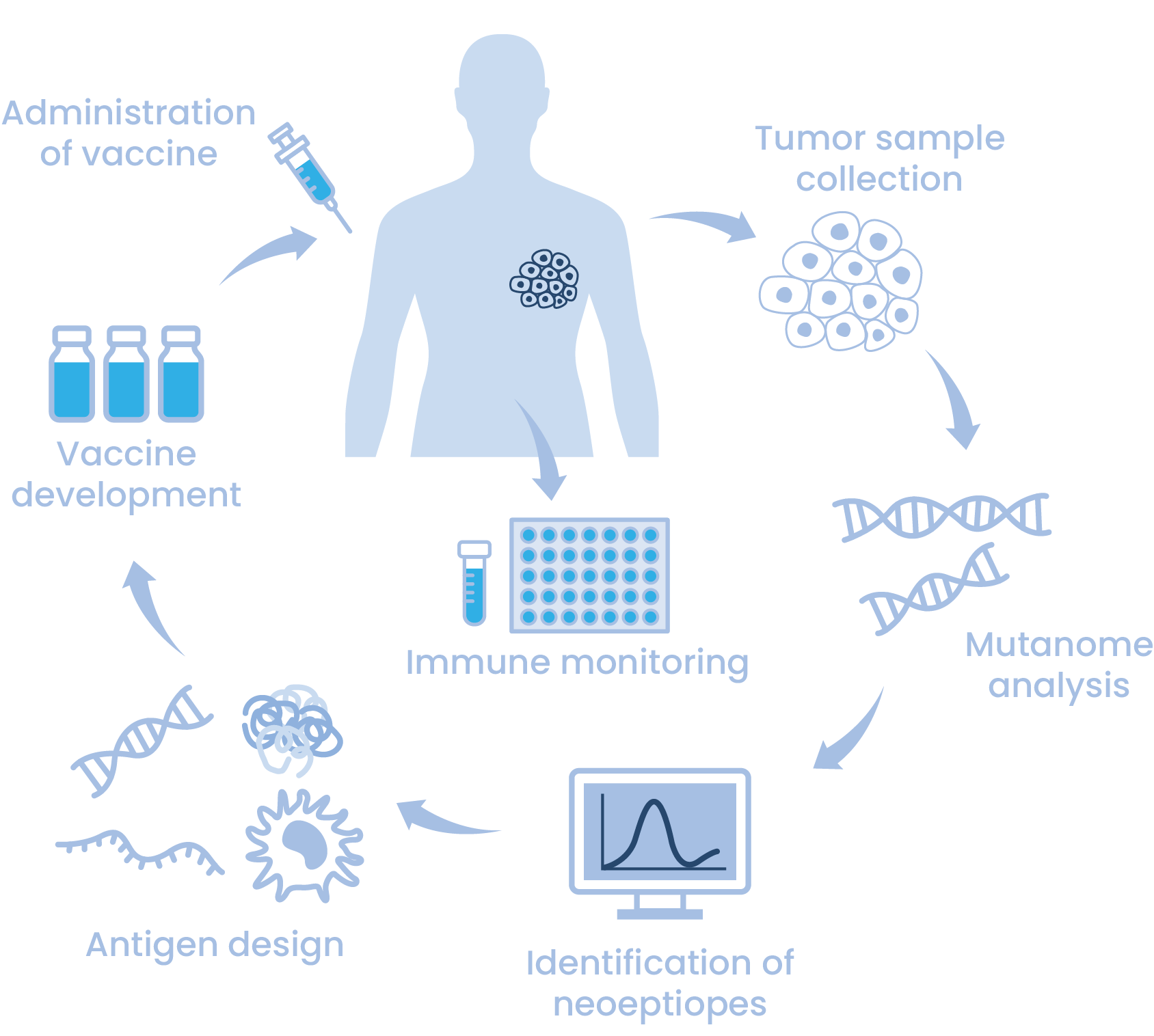
미래에 유망한 항암 면역치료 방법 중 하나로, 최근 환자 맞춤형 암백신(personalized cancer vaccine)에 대한 관심이 급증하고 있습니다. 환자 맞춤형 암백신은 각 암환자의 암세포에 존재하는 돌연변이 전체(mutanome)를 파악하고 이러한 돌연변이들 내에서 T세포 에피토프로 작용할 수 있는 부분을 찾아내어 이를 암 치료백신으로 제조하고 환자에게 투여하는 것입니다. 이 때 암세포에 존재하는 수많은 돌연변이들 중 어느 부분이 항암 면역 반응을 유발할 T세포 에피토프가 될지를 결정하는 보다 정확하고 효율적인 항원 예측기술이 필요합니다.
Identification of Neoepitopes
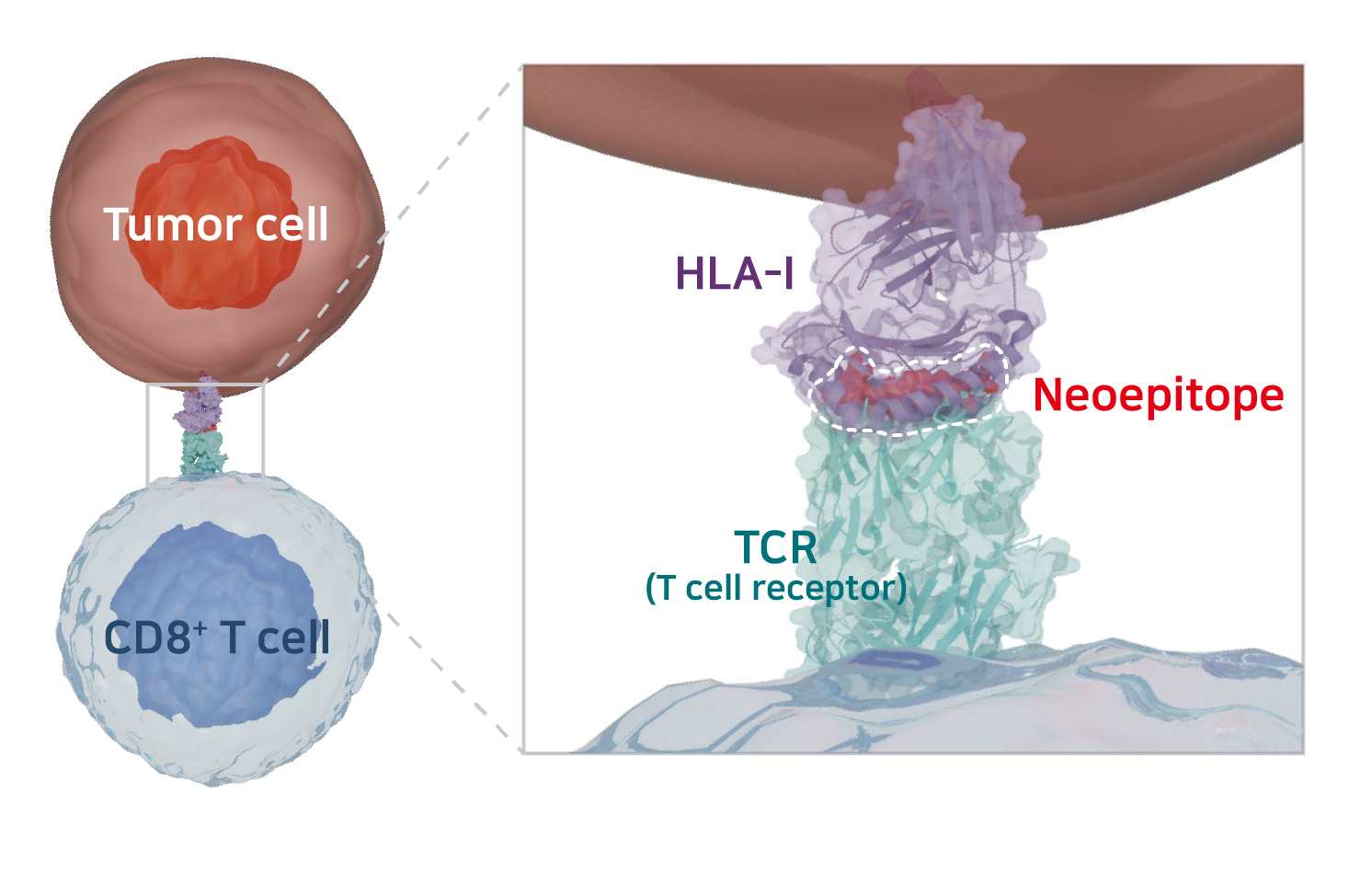
암세포 내에서 발생한 돌연변이로 인해 생성된 항원을 신생항원(neoantigen)이라고 하며, 신생항원은 기본적으로 HLA 분자에 결합하여 T세포를 자극하는 T세포 에피토프(neoepitope, 신생항원 에피토프)가 됩니다. 변이된 암세포의 존재를 인지하고 선택적으로 죽여서 제거할 수 있는 CD8+ T세포가 환자 몸 안에서 제대로 작동할 수 있게 하는 것이 환자 맞춤형 암백신의 궁극적인 목표입니다.
다만 환자의 HLA 다양성 및 일부 펩타이들의 HLA 결합능과 T세포 반응 유도능 간의 불일치 등 신생항원 에피토프의 예측을 어렵게 하는 여러 요인들로 인해 현재까지의 기술로는 신생항원 에피토프 예측 정확도가 높지 않은 상황입니다.
암백신 개발을 위한 신생항원 발굴의 핵심 극복과제
사람마다 매우 다양한 HLA-I allotype 보유
표본 실험 데이터 적용 한계성
연역적 예측의 한계
기존 AI기반 접근방식 데이터의 낮은 정확도
HLA-I 결합 펩타이드의 일부만 T세포 반응 유도
HLA-I에 결합하지만 T세포 반응을 유도하지 않는 펩타이드는 암백신 효능 저해
Scientific Strategies of TCELLOGY
신생항원 발굴을 위해 현재까지 발표된 다양한 에피토프 데이터베이스를 기반으로 만들어진 예측 알고리듬들이 개발되고 있으나 이러한 기술들의 정확도는 실제 암백신 개발에 적용 가능한 수준에는 미치지 못하고 있습니다.
핵심적인 이유는 이러한 예측 알고리듬을 만들기 위해 이용한 T세포 에피토프들의 데이터가 제한적이고 실험 간 여러 변인 요소가 존재하는 데이터들을 소스로 사용했기 때문입니다. 기계학습을 통한 인공지능의 수단을 이용하여 좋은 예측 알고리듬을 만들기 위해서는 학습시킬 데이터베이스의 크기가 충분히 커야 하는데, 현재 알려진 T세포 에피토프들의 데이터가 충분히 많지 않기 때문에 생기는 문제점입니다.
티쎌로지는 이러한 문제점을 해결하기 위해 오랜기간 축적한 인간 T세포 면역학 기술을 통해 대규모의 신규 에피토프 데이터를 새롭게 발굴하고 실험적으로 검증하여 T세포 에피토프들의 데이터베이스 크기를 충분히 늘려 보다 정밀한 예측 알고리듬을 개발함으로써 보다 정확한 신생항원 예측 기술 서비스를 제공할 것입니다.
Database 구축
in vitro 실험으로 T세포 에피토프를 대규모로 발굴하여 DB 구축
HLA-I 결합 펩타이드 중 T세포 반응 유도 및 비유도 펩타이드에 대한 DB구축
알고리듬 개발
AI 분석을 통하여 고빈도 HLA-I allotype에 대한 신생항원을 정확히 예측하는 알고리듬 개발
T세포 반응 유도 펩타이드 DB 와 비유도 펩타이드 DB를 동시에 활용하여 예측 정확도를 획기적으로 향상